■アドミッションコントロール
VMware HAによって保護された仮想マシンがほかのESXiホストで確実にフェイルオーバーできるようにするためにはクラスタの各ESXiホストにフェイルオーバー用に予備リソースを確保する必要があります。ホスト上で予備リソースを確保できないと判断した場合、仮想マシンのパワーオンなどの追加リソースの消費を制限します。これをアドミッションコントロールといいリソース不足のときには次の動作が禁止されます。
○仮想マシンのパワーオン
○ホスト、クラスタ、、リソースプールへの仮想マシンの移行
○仮想マシンのCPUやメモリの予約値の増加
また、アドミッションコントロールを行うために予備リソースを確保する方法として次の3つのポリシーから選択可能です。
○ホスト障害のクラスタ許容台数
○フェイルオーバーの予備予約容量として予約されたクラスタリソースの割合
○フェイルオーバーホストの指定
上記のポリシーの詳細を以下に記載します。
■ホスト障害のクラスタ許容台数
アドミッションコントロールとして「ホスト障害のクラスタ許容」を選択し、台数を指定した場合、指定した台数までのホストに障害が発生しても全ての仮想マシンがフェイルオーバーできるよう仮想マシンのリソース消費をコントロールします。
何台までのホスト障害であればそのホスト上で動作している全ての仮想マシンを復旧できるか判断するためHAクラスタの現在のリソース使用状態をもとに予備リソースを計算します。個のホストの冗長性をフェイルオーバーキャパシティと呼びます。フェイルオーバーキャパシティを計算するためにスロット、スロットサイズ、スロット数という概念を導入します。
スロットとは仮想マシンのリソースサイズを定型化したものです。一般に消費するリソースの量は仮想マシンごとに異なるため、フェイルオーバーキャパシティを簡単に計算することはできません。その計算を単純化するため全ての仮想マシンがスロットという同一のサイズのリソース ( スロットサイズ ) を使用していると仮定し、各ホストでどれだけの数の仮想マシンが動作可能 ( スロット数 ) か、またホスト障害時にクラスタ内のほかのホストにどれだけのスロットの余裕があるか判断することで、フェイルオーバーキャパシティを計算します。
●スロットサイズの算出
パワーオン中の仮想マシンのうち、CPU予約値が最大のものがCPUスロットとなります。仮想マシン全てに予約値が設定されていないと正確に計算されないことになりますので注意が必要です。そしてパワーオン中の仮想マシンのうちメモリ予約値が最大のものがメモリスロットサイズとなります。こちらもメモリ予約値が設定されてないと正確に計算されませんので注意してください。
例えば以下の構成の場合

VM1-3の間でCPUが2Ghz、メモリが2GBが最大値となりますので、これらがスロットサイズとなります。また、他にESXiホストが存在する場合はそれらも比較対象として最大値を求める必要があります。
●ホストごとのスロット数の算出
ホストごとにCPU、メモリの物理リソースサイズをスロットサイズで割り、小さいほうをスロット数として算出します。以下の構成で考えてみます。CPUスロットサイズが2Ghz、メモリスロットサイズが2GBという前提で小数点以下は切り捨てとなります。

| CPU総容量 | メモリ容量 | スロット数 | |
| ESXi A | 9Ghz ( 9/2 = 4.5 ) = 4 | 2G ( 2/2 ) = 1 | 1 |
| ESXi B | 6Ghz ( 6/2 = 3 ) = 3 | 4G ( 4/2 ) = 2 | 2 |
| ESXi C | 12Ghz ( 12/2 = 6 ) = 6 | 3G ( 3/2 = 1.5 ) = 1 | 1 |
CPUとメモリのスロット数の小さいほうがそのESXiホストのスロット数となります。このスロット数が各ホストで稼働できる仮想マシンの数ということになります。
これらが実際にどのように計算されているかはvSphere Clientの中のクラスターのサマリタブの中で「詳細ランタイム情報」をクリックすると表示されます。

上記をクリックすると現在の予約値をもとに計算したスロット数が表示されます。
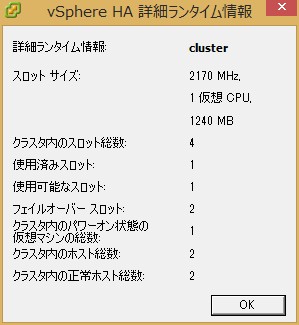
●フェイルオーバーキャパシティの算出
HAクラスタ内のホストのうち、物理リソースサイズが最大のホストに障害が発生すると仮定します。残りのホストのスロット数を合計し、この数がパワーオン中の仮想マシンの合計より多いか比較します。多い場合はこのホストに障害が発生してもキャパシティに余裕があると判断しフェイルオーバーキャパシティは1台以上と判断されます。
さらに2番目の物理リソースが大きいホストに障害が発生すると仮定し、1番目と2番目のホストを除いた残りのホストのスロット数の合計がパワーオン中の仮想マシンの数より多いか比較します。スロットの合計が仮想マシンの数より多い場合はキャパシティは2台以上と判断されます。
このように物理リソースの多いホストから順番に障害が発生すると仮定し残りのホストの合計スロット数がパワーオン中の仮想マシンの数を下回るまで繰り返します。下回らない最大障害台数がキャパシティとなります。
■予約されたクラスタリソースの割合
このポリシーはクラスタ全体のCPU、メモリのリソースの合計に対して一定以上のリソースとして予約しておく手法です。キャパシティの算出方法は以下の通りです。
1. パワーオン中の仮想マシンのリソースの合計
パワーオンされている仮想マシンのCPUおよびメモリの予約の合計値を算出します。予約の値をもとに計算しますので仮想マシンには予約リソースが割り当てられていることが前提です。
2.クラスタ内のホストのリソースの合計
クラスタ内のホストのCPUおよびメモリの合計値を算出します。これはvSphere Clientのクラスターのサマリ画面から確認可能です。
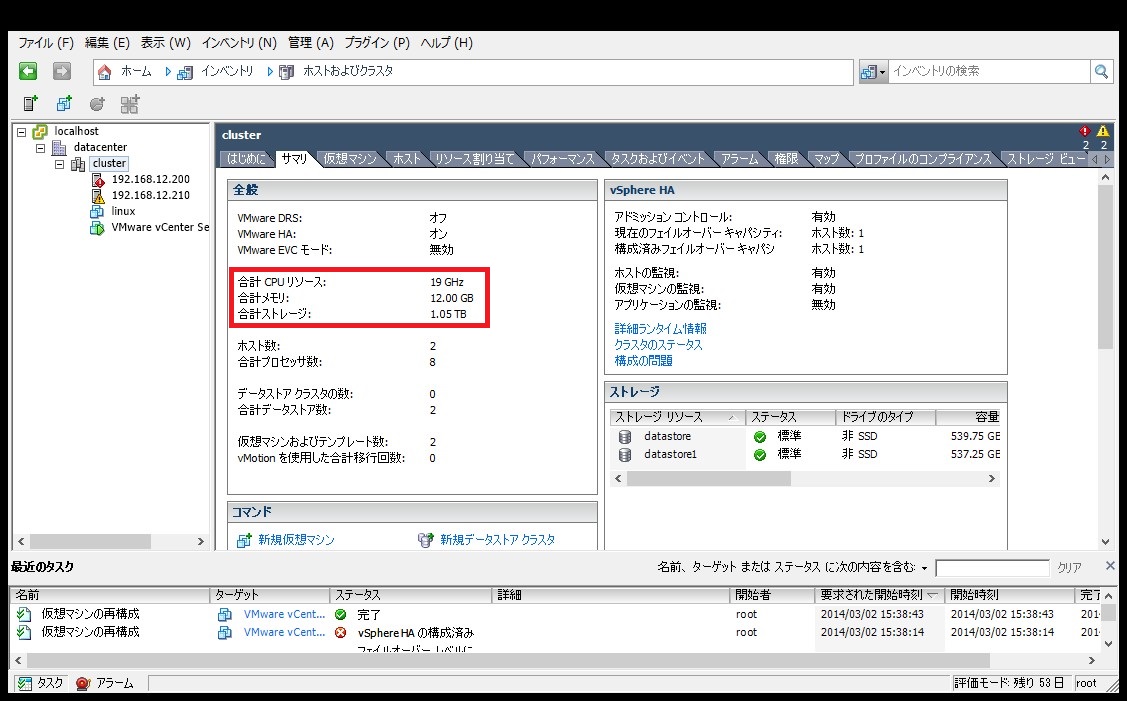
3.キャパシティの算出
以下の計算式によりフェイルオーバーキャパシティを算出します。
CPU : ( ホストの合計CPU – 仮想マシンの合計予約CPU ) / ホストの合計CPU
メモリ : (ホストの合計メモリ-仮想マシンの合計予約メモリ) / ホストの合計メモリ
例えば以下の場合、
ホスト合計CPU : 30Ghz
ホスト合計メモリ : 30G
仮想マシン合計予約CPU : 10Ghz
仮想マシン合計予約メモリ : 10G
次の計算式でフェイルオーバーキャパシティが計算できます。
CPU : ( 30Gzh – 10Ghz ) / 30Ghz = 約66%
メモリ : ( 30G – 10G ) / 30G = 約66%
これらの値がオプションで指定した値を下回らない限りフェイルオーバーは問題なく実施されます。
■フェイルオーバーホストの指定
このポリシーは最も単純明快な仕組みで予めクラスターの中の特定のホストをフェイルオーバー専用として予約しておきます。これは1台のみ設定可能です。
指定されたホスト上では仮想マシンのパワーオン、vMotionやDRSによる移行は禁止され仮想マシンが常に稼働していない状態に保たれます。ホスト障害時にはデフォルトで指定したホスト上で仮想マシンが再起動されますがフェイルオーバーホストに障害が発生している、またはリソースが足りないなどの理由により仮想マシンが再起動できない場合はほかのホスト上で再起動されます。